工业互联网大数据综合实训中心是由西北工业大学工业互联网实训基地主体承担建设,面向工业企业典型应用场景,具备先进的培训理念和标准化的课程体系的一流实训中心。实训中心占地200m²,提供高度弹性可扩展云存储的硬件服务,搭建分布式大数据集群,包含大数据体系框架,可进行完整的工业大数据项目实训、实施。

实训基地环境图
该实训硬件环境以化工企业二氧化碳吸收工艺为原型进行设计,涵盖
l 皮带质量监测系统
l 声学识别设备故障系统
l 热象数学双胞胎系统
l 化工吸收塔二氧化碳补集系统
四个模块,通过传感器、摄像机等多种方式采集结构化和非结构化数据,云计算和大数据处理平台调用各专业处理软件和算法等。可同时接纳30名学生开展实训活动,让学生和从业人员在实践中学习和掌握技能。
实训硬件环境主要设备系统连接图
硬件资源方面配备1台云桌面服务器,1台云管理集群服务器,30台学员电脑,30个实训工位。
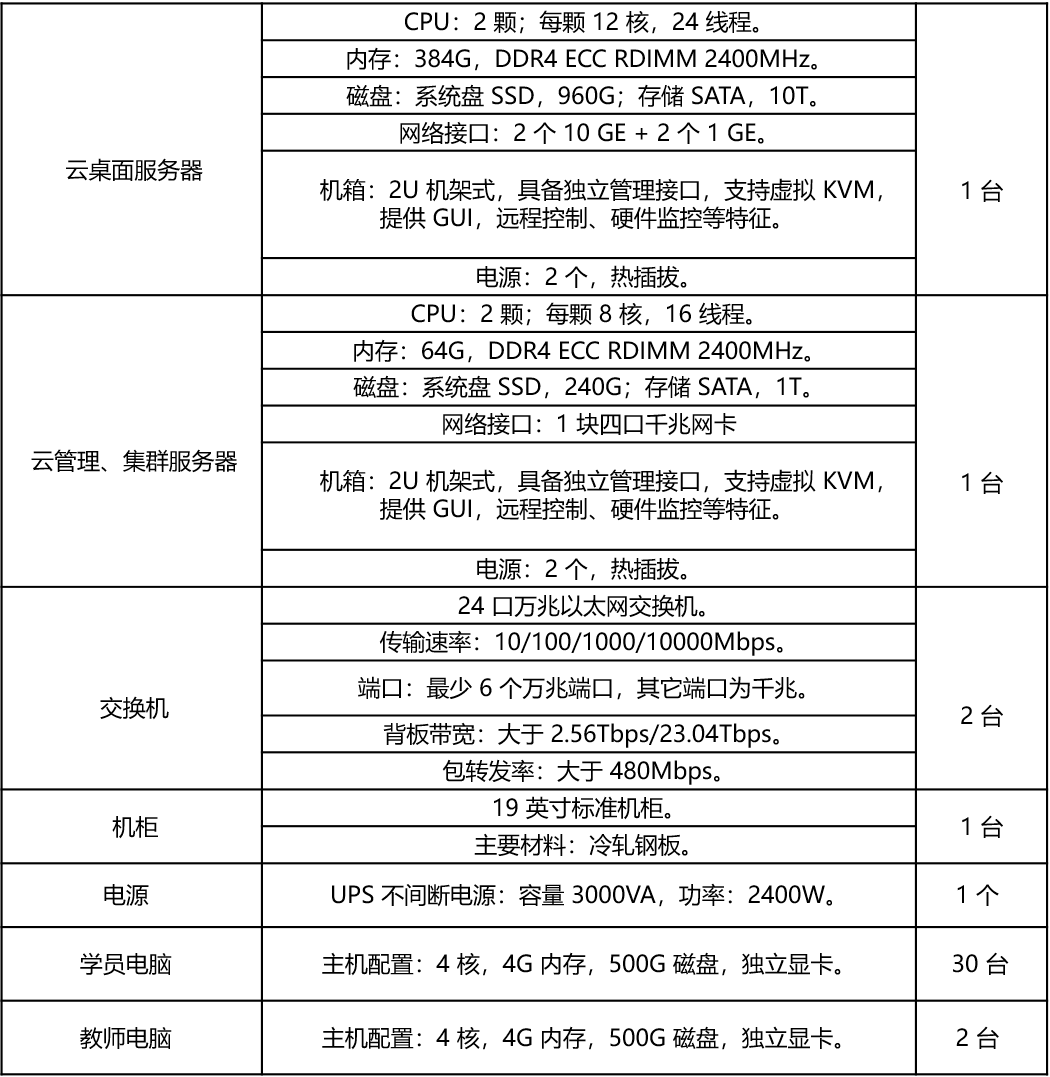
硬件资源配置图
1、软件系统

软件系统图
1)Hadoop
Hadoop 是一个提供分布式存储和计算的开源软件框架,它具有无共享、高可用(HA)、弹性可扩展的特点,非常适合处理海量数量。三大核心组件:HDFS(分布式文件系统) 、MAPREDUCE(分布式运算编程框架)、YARN(分布式资源调度系统)
2)Kafka
Kafka是一种消息队列,主要用来处理大量数据状态下的消息队列,一般用来做日志的处理。具有解耦合、异步处理、流量削峰的优势。
3)HBase
HBase 是一个面向列式存储的分布式数据库,其设计思想来源于 Google 的 BigTable 论文。HBase 良好的分布式架构设计为海量数据的快速存储、随机访问提供了可能,基于数据副本机制和分区机制可以轻松实现在线扩容、缩容和数据容灾,是大数据领域中Key-Value 数据结构存储最常用的数据库方案。
4)Spark
Spark 是当今大数据领域最活跃、最热门、最高效的大数据通用计算平台之一。适用于各种各样原先需要多种不同的分布式平台的场景,包括批处理,迭代算法,交互式查询,流处理。
2、硬件系统
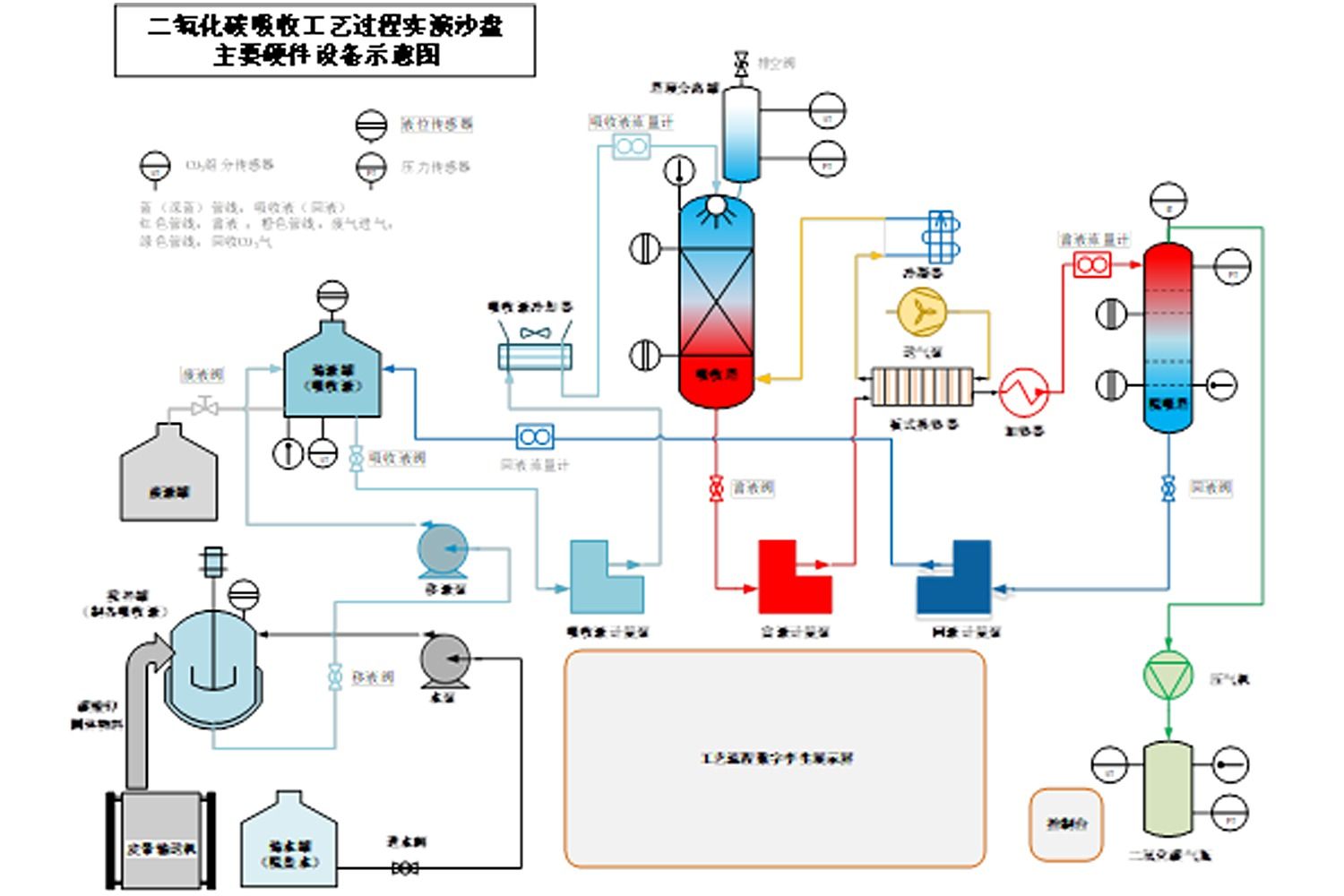
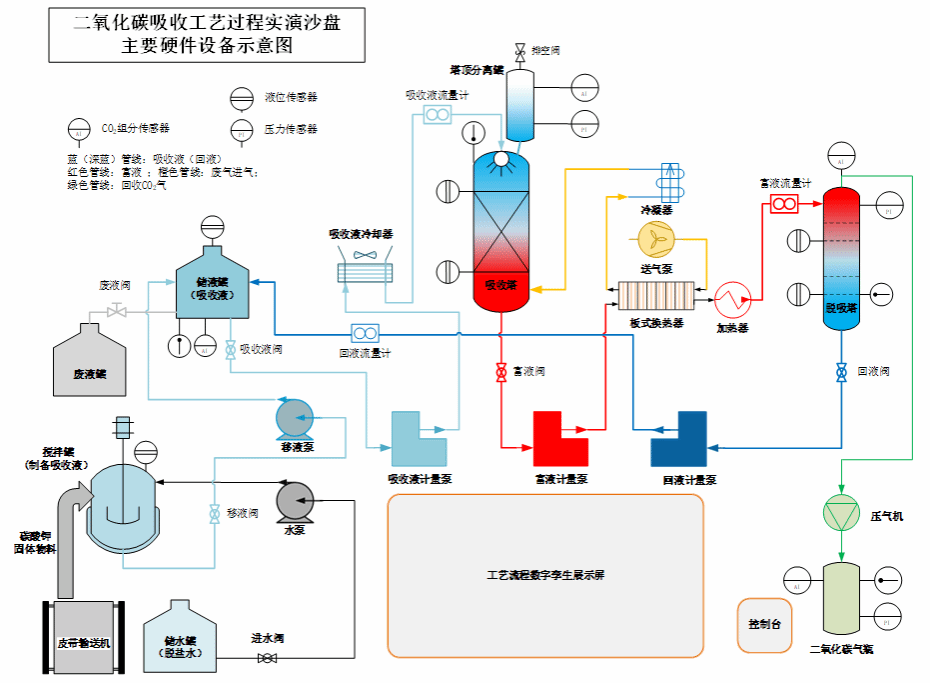
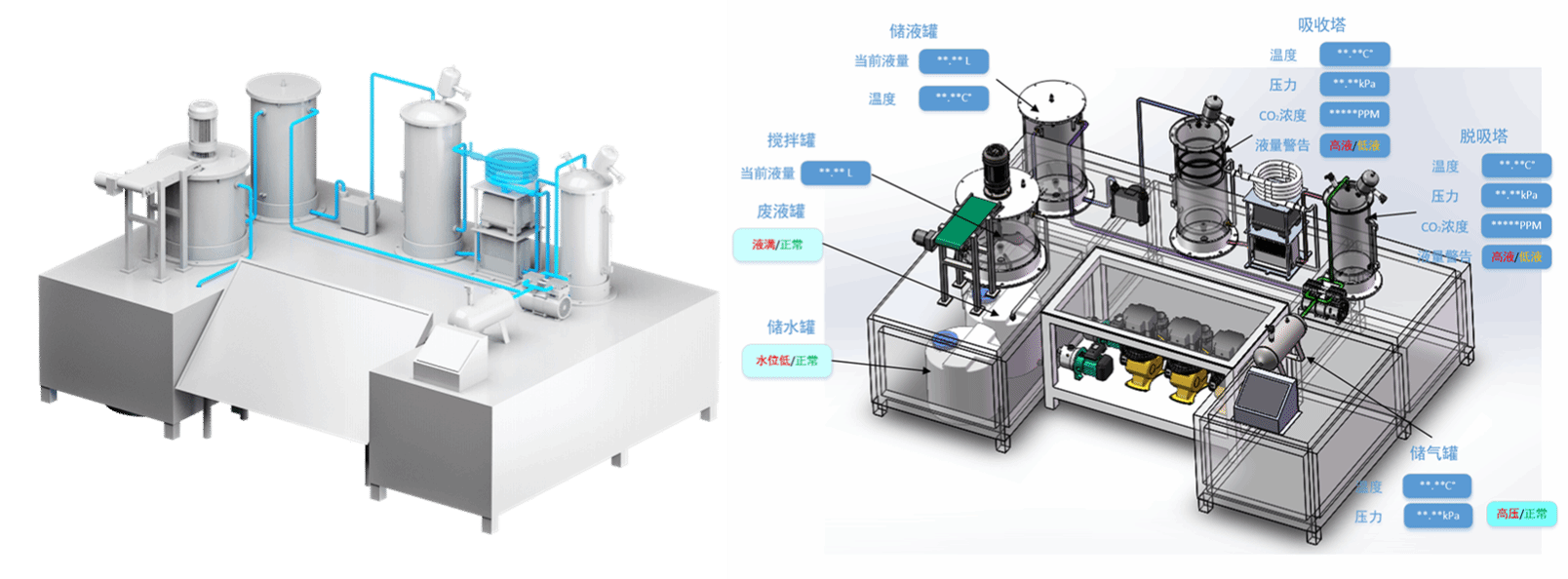
主要包含一套教学用的CO2的捕集工艺小试装置,二氧化碳吸收工艺过程如图1所示。该模块硬件主要包括输送设备、物料容器、动力泵、热交换设备、电控设备、传感测量设备、阀门以及管材管件等。二氧化碳吸收工艺过程实演沙盘主要硬件设备如图2所示,软件依托工业PLC控制软件实现工艺流程控制、数据采集和数据传输等功能。
输送设备包括:碳酸钾固体物料皮带输送设备
物料容器包括:储水罐、搅拌罐、储液罐、废液罐、吸收塔、吸脱塔、塔顶分离罐、CO2储气瓶。
动力泵包括:水泵、移液泵、吸收液计量泵、富液计量泵、回液计量泵、送气泵、压气机。
热交换设备包括:吸收液冷却器(强排风冷)、板式换热器、冷凝器和加热器。
电控设备:供电电源、控制电柜、触控控制台等。
仪表设备:温度、压力、流量、液位、CO2传感设备等。
管材管件:连接管道、管件等。
实训硬件环境主要设备示意图
1、实训课程
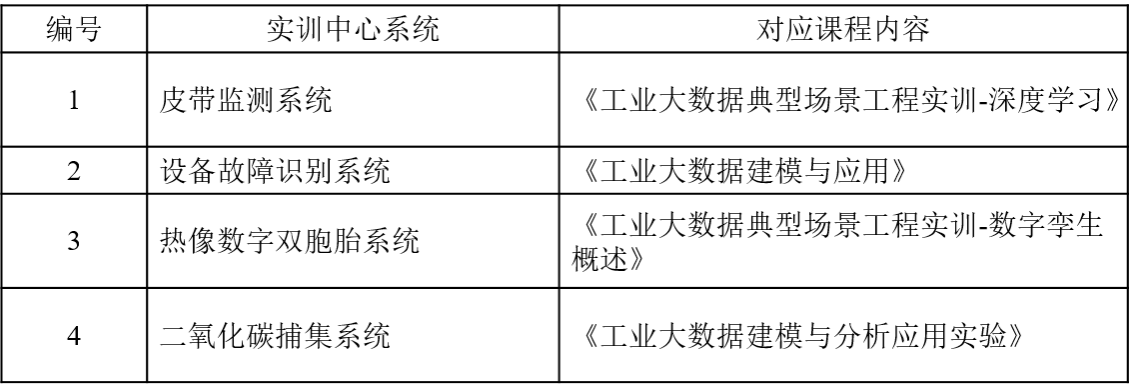
实训中心与课程对应情况如下表所示
《工业大数据典型行业应用场景工程实训》课程主要包含以下实训课程内容:
1)基于大数据的皮带生产质量监测系统实训课程
模拟皮带生产线,建立机器视觉人工智能培训样例,结合工业互联网运作体系,使学员了解掌握工业互联网人工智能如何服务于工业生产。
2)声学识别设备故障系统实训课程
模拟泵站环境,建立拾音监测人工智能培训样例,结合工业互联网运作体系,使学员了解掌握服役设备+声学阵列+工业互联网人工智能进行工业生产故障诊断和设备管理方法。
3)热像数字双胞胎系统实训课程
输出完整的热象DT场景及建模工具,建立热像数字双胞胎系统,让学员了解掌握工业生产中安全巡视的热象DT业务。
4)化工吸收塔二氧化碳捕集系统(基于工业大数据分析)
在工业互联网平台中,建立二氧化碳吸收单元的数字双胞胎,采集塔顶温度、压力、吸收液流量,吸收前后空气中二氧化碳浓度,并以实际沙盘+数字孪生模型进行实时展示,让学员了解掌握数字孪生和工业大数据分析方法在工业生产中的应用。
2、课程案例
以设备故障识别系统为例,利用《工业大数据建模与应用》中数据预处理、特征工程、数据建模、模型可视化等知识和技术实现具体设备的实时运行状态分析和展示,并对设备故障进行预测性识别。


联系电话:
029-812-90192

提交成功!








